Streaming Tweets to InfluxDB in Node.js
This week, I've been exploring the InfluxData tech stack. As a muse, I decided to move some of my social media sharing patterns formal algorithms. I also want to use my blog as a source for keywords, filter out profanity, and apply sentiment analysis to clarify relevant topics in the tweets.
Github repo for this article: github.com/paulsbruce/InfluxTwitterExample
What Is InfluxData?
Simply put, it's a modern engine for metrics and events. You stream data in, then you have a whole host of options for real-time processing and analysis. Their platform diagram speaks volumes:
[caption id="attachment_768" align="alignnone" width="840"]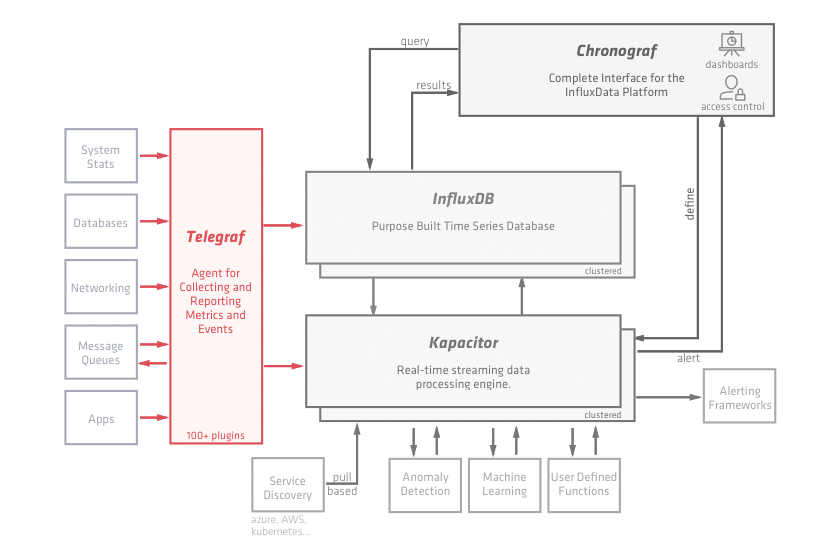 From InfluxData.com Telegraph Overview[/caption]
From InfluxData.com Telegraph Overview[/caption]
Based on all open source components, the InfluxData platform has huge advantages over other competitors in terms of extensibility, language support, and its community. They have cloud and enterprise options when you need to scale your processing up too.
For now, I want to run stuff locally, so I went with the free sandbox environment. Again, completely open source stack bits, which is very cool of them as lots of their work ends up as OSS contributions into these bits.
Why Process Twitter Events in InfluxDB?
Well, frankly, it's an easy source for real-time data. I don't have a 24/7 Jenkins instance or pay-for stream of enterprise data flowing in right now, but if I did, I would have started there because they already have a Jenkins data plugin. :)
But Twitter, just like every social media platform, is a firehose of semi-currated data. I want to share truly relevant information, not the rest of the garbage. To do this, I can pre-filter based on keywords from my blog and 'friendlies' that I've trusted enough to re-share in the past.
The point is not to automatically re-share content (which would be botty), but to queue up things in a buffer that would likely be something I would re-tweet. Then I can approve or reject these suggestions, which in turn can be a data stream to improve the machine learning algorithms that I will build as Kapacitor user-defined functions later on.
Streaming Data Into InfluxDB
There's a huge list of existing, ready-to-go plugins for Telegraph, the collection agent. They've pretty much thought of everything, but I'm a hard-knocks kind of guy. I want to play with the InfluxDB APIs, so for my exploration I decided to write a standalone process in Node.js to insert data directly into InfluxDB.
To start, let's declaring some basic structures in Node to work with InfluxDB:
const dbname = "twitter";
const measure = "tweets";
const Influx = require("influx");
const influx = new Influx.InfluxDB({
host: "localhost",
database: dbname,
schema: [
{
measurement: measure,
fields: {
tweetid: Influx.FieldType.INTEGER,
relevance: Influx.FieldType.FLOAT,
user: Influx.FieldType.STRING,
volatile: Influx.FieldType.BOOLEAN,
raw: Influx.FieldType.STRING
},
tags: [
"keywords"
]
}
]
});
- dbname: the InfluxDB database to insert into
- measure: the measurement (correlates to relational table) to store data with
- fields: the specific instance data points to collect on every relevant Tweet
- tags: an extensible list of topic-based keywords to associate with the data
Making Sure That the Database Is Created
Of course, we need to ensure that there's a place and schema for our Twitter data points to land as they come in. That's simple:
influx.getDatabaseNames()
.then(names => {
if (!names.includes(dbname)) {
return influx.createDatabase(dbname);
}
});
Saving Pre-screened Tweets as InfluxDB Data Points
Minus the plumbing of the Twitter API, inserting Tweets as data points to InfluxDB is also very easy. We simply need to match our internal data structure to than of the schema above:
// after processing, save Tweet result to InfluxDB directly
function saveTweetToInflux(result) {
influx.writePoints([
{
measurement: "tweets",
tags: { // array of matched keywords
keywords: (result.tags.length > 0 ? result.tags.join(",") : [])
},
fields: {
tweetid: result.tweetid, // unique tweet id
relevance: result.relevance, // 0.0 to 1.0 for later analysis
user: result.user, // original twitter user
volatile: result.volatile, // contains blocked words?
raw: JSON.stringify(result) // complete tweet for later analysis
},
}
]).catch(err => {
console.error(`Error saving data to InfluxDB! ${err.stack}`);
});
}
Notice that the keywords (tags) can be a simple Javascript array of strings. I'm also optionally inserting the raw data for later analysis, but aggregating some of the most useful information for InfluxQL queries as fields.
The InfluxDB Node.js client respects ES6 Promises, as we can see with the '.catch' handler. Huge help. This allows us to create robust promise chains with easy-to-read syntax. For more on Promises, read this article.
Verifying the Basic Data Stream
To see that the data is properly flowing in to the InfluxData platform, we can use Chronograf in a local sandbox environment and build some simple graphs:
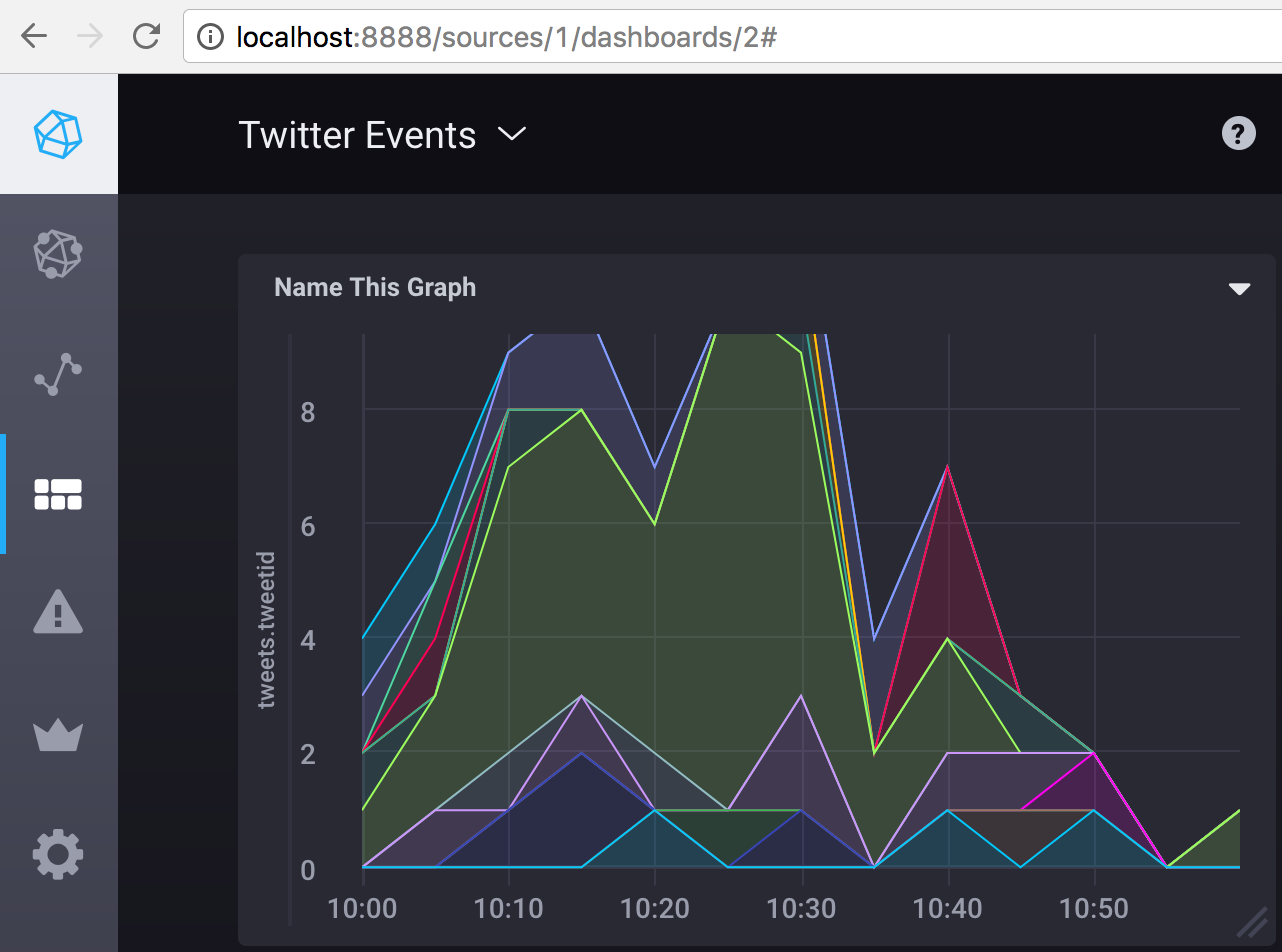
To do this, we use the Graph Editor to write a basic InfluxQL statement:
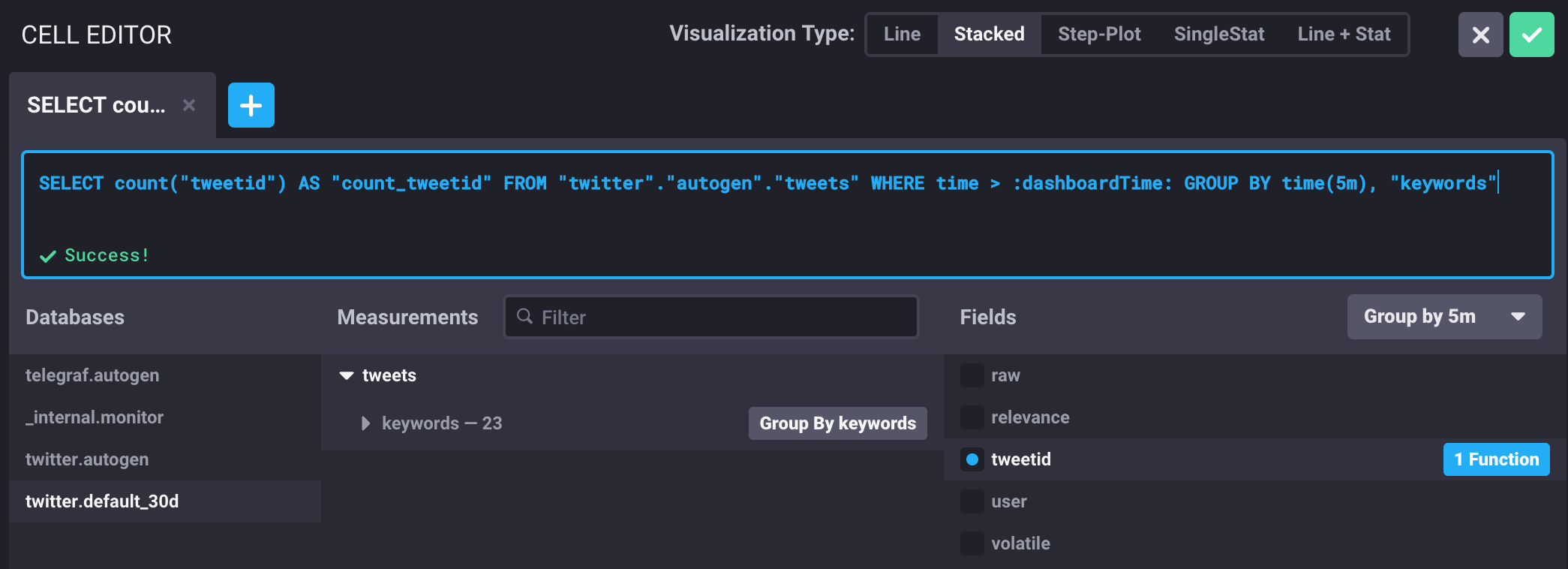
SELECT count("tweetid") AS "count_tweetid"
FROM "twitter"."autogen"."tweets"
WHERE time > :dashboardTime:
GROUP BY time(5m), "keywords"
The simple graph shows a flow of relevant tweets grouped by keyword so we can easily visualize as real-time data comes in.
A Few Ideas and Next Steps
Of the many benefits of processing data on the InfluxData platform, processing in Kapacitor seems to be one of the most interesting areas.
Moving forward I'd like to:
- Move Sentiment Analysis with Rosette from Node into Kapacitor
- Add Machine Learning into Kapacitor for
A) clarifying relevance of keywords based on sentiment entity extraction
B) extract information about the positivity / negativity of the tweet - Catch high-relevance notifications and send to Buffer 'For Review' queue
A) accepts and rejects factor back into machine learning algorithm
B) follow-up statistics about re-shares further inform ML algorithm - Have Kapacitor alert when:
A) specific high-priority keywords are used (use ML based on my tweets)
B) aggregate relevance for a given keyword spikes (hot topic)
C) a non-tracked keyword/phrase is used in multiple relevant tweets
(could be a related topic I should track, event hashtag, or something else)
As You Build Your Own, Reach Out!
I'm sure as I continue to implement some of these ideas, I'll probably need help. Fortunately, Influx has a pretty active and helpful Community site. Everything from large exports, plugin development, and IoT gateways are discussed there. Jack Zampolin, David Simmons, and even CTO Paul Dix are just a few of the regular contributors to the conversation over there.
And as always, I like to help. As you work through your own exploration of InfluxData, feel free to reach out via Twitter or LinkedIn if you have comments, questions, or ideas.