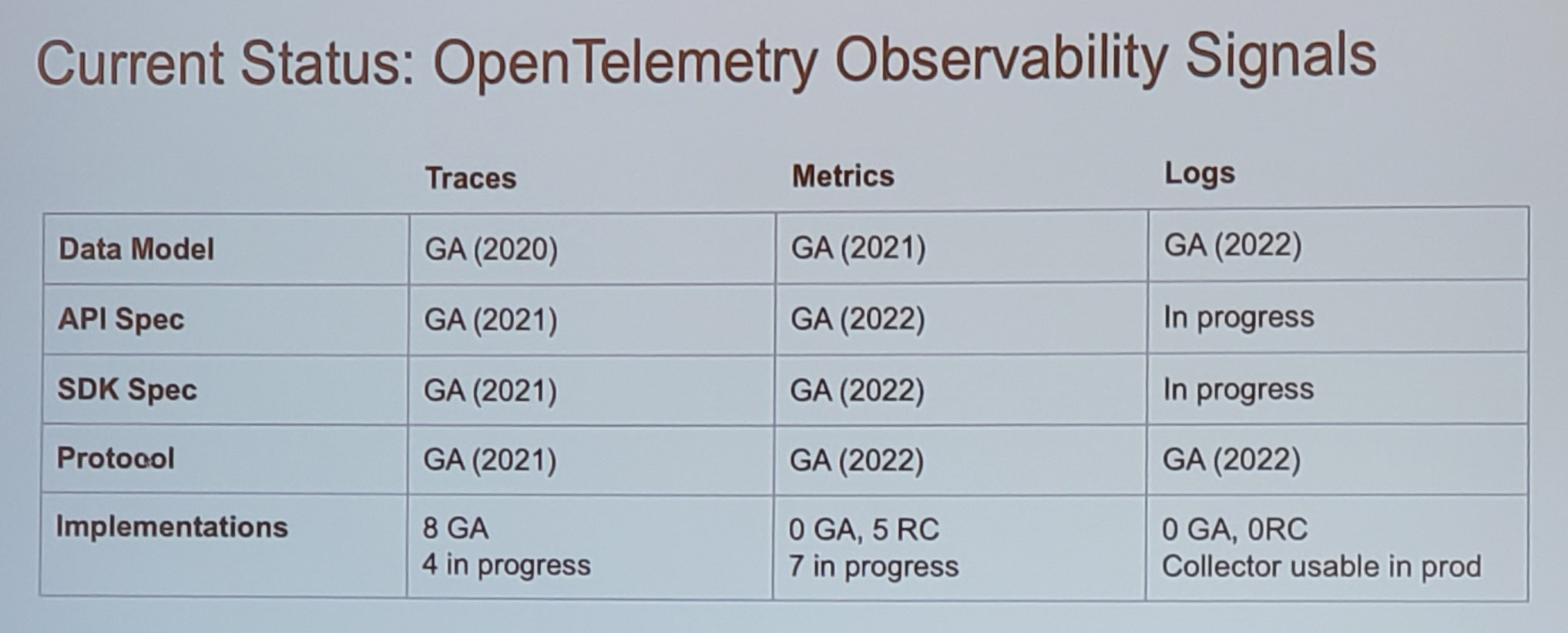
It’s been just over two months since I last posted because I’ve been busy working on multiple fronts and underprioritizing post-facto documentation to that end. I plan to shorten the cycles between my works and my posts, but most of the real-time is on LinkedIn for reasons that become obvious immediately below.
- Each morning, doing what I call ‘Career Prospecting’ for at least 2 hours; vendors, edus, etc.
- Non-profit entrepreneurial work on a new project I call ‘Indy AG Tech’
- Volunteering with a few local farms to “surround myself with context” about the above
- Still working with the DevOpsDays organizers on this year’s event October 21-22
- Driving the Boston DevOps meetup, last month a BYO potluck style on a Roof Park
Career Prospecting
Largely this consists of looking at full-time employment opportunities online and then executing on the (minimally sufficient) options available. I am still in the mindset of being ‘choosy’ because after 25 years working in tech, much of the early as a developer then the past 10 years doing everything else that brings more context (and money), it would be irresponsible of me to simply give in to ‘the old ways’ or find a totally different career out of curiosity. My criteria consist of:
- leadership with a demonstrated track record of good decisions
- culture that encourages Westrum generative characteristics wherever appropriate
- high degree of overlap with my 20 years honed business and tech skill sets
- employees in/representing a variety of locations and perspectives (not simply the U.S.)
- pay range and career growth opportunities that (ast least) meet my median requirements
More on my thoughts about good vs. bad company signals in footnotes.
Recently a tech-scuba friend of mine posted something enlightening about this time-spend, that contracting is viable, if not just under the economic circumstances but also in general (knowing him enough to read between) that our full-time economic employment model in high-tech has failed so miserably that we all should just look for situations where people pay us for what’s produced/rendered. This reminds me of a Monteiro-ism: “F*ck you, pay me” which is worth consideration in this regard.
All that said, just about every day I exhaust the patience I have to find some meaningful full-time gig with a company that is worth my time. There is lots of fear-uncertainty-doubt in managers right now, particularly going in a (likely soon) recession. But there is still work to do and those that don’t make good decisions (hopefully with me in them) most certainly will be judged later.
Enough about that necessary time-spend per weekday.
‘Indy AG Tech’ Preface
I was a boy grown up in a garden. Granted, this inferred land and skin privilege but definitely not the economic or social kind. We also had a ton of blueberries for a month or so per year and fruit trees spread around. If only I could give the non-skin aspects of this privilege to every kid everywhere I would, but I can’t outright. We made no more than $50k/year max my whole in-house years. In 90’s terms, this is comparative now to twice that. Score one for inflation, score less than that for cost of living. I made my own games up, spent a lot of time outside with chores and play, re-invented how far legos could go. Fun wasn’t really ever the goal…working problems out was.
All that said, I garden now. For almost 20 years, I’ve been iterating on what produces useful output on a rental roof, importing necessary inputs and only exporting necessarily so’s. Gardeners with the luxury of space, soil, inputs, funding, and/or lack of learning requirements deserve the callers they inspire with their sometimes-sponsored ‘radio’ podcasts. The rest of us are on a mission to do something useful in our local areas, feeding others or saving the world in some small or large ways. This is the ‘Indy’ (independent) part of the AG(ricultural) application of tech; no organization has any better ethics and passion than the people working within it. We are all individual contributors to that end.
So I’ve converted some of my demonstrably useless prior corporate timespend into meaningful discovery on “real problems”. The one that hits hardest is how independent agriculture (particularly small and mid-sized family farms) just about everywhere is systematically being divested from, of course by for-profit corporations but also by governmental bodies. Look hard enough and public data sets such as the 2012-2022 USDA Agricultural Survey data and you’ll see what I mean:
- government subsidies to farms with under $1M in revenue are decreasing by ~33% year-over-year
- government subsidies to farms with over $2.5M in revenue are increasing by 300%
- in the past 10-12 years, the U.S. lost 219,047 small/mid-sized family farms
- increases to other filing status tabulations (e.g. ‘corporate’), orders of magnitude fewer than above loss in family farms; this is consolidation to macro-farms or other developments
- decreases in beef, dairy, and fishing exports
- decreases in exports from agricultural producers under $5M yearly revenue
Separately, and IMO not uncoincidentally:
- decreases in natality rate (Aug 2024)
- increases in mortality rate (May 2024?)
- PFAS, microplastics, pesticide and food-borne illnesses
- further erosion and degradation of large farmable lands
‘Indy AG Tech’ and Real Field Discovery
So I’ve been volunteering on local farms to surround myself with and gain context. As all early thought processes go, later deep-dive into ‘real’ challenges leads to initial assumptions being debunked by better information from people actually experiencing those challenges.
Recent personal examples of early assumptions supplanted by ‘earned context’ are:
- Physical robotic vs. human field assistance (re: drones herding sheep vs. camera-captured diffs of plans and field yields)
- The impetus vs. perceptions of ‘voluntary efforts’ and legalities therein
- Give-to-get vs. iterative reciprocations of trust systems
- ‘High thinking’ vs. ‘apparent value’ between tech and field advisors
- The time it takes for a 40+ tech physiology to re-acclimate to hard physical labor
Beyond lots of weeding, hoeing, hilling potatoes, pulling onions, more weeding, transplanting, and anything else that needs muscles, there are a few key areas where my prior ‘high tech’ experiences seem to apply:
- intelligent management (sense and respond) systems for greenhouses
- in-field use of voice driven solutions for observed issue research and all manner of reminders
- drone-based visualization, assessment, and comparison of field conditions
- use cases for ‘not always connected’ field monitoring
None of these problem areas are ‘not yet sufficiently solved’ but there are no good or successful combinations of tech which A) non-proprietarily and B) affordably for small/mid-sized farm owners solve the problem(s). Most AG tech mobile apps available through consumer marketplaces only scratch the surface of true ‘management’ of these concerns. Otherwise the rest of the more complete solutions are geared toward ‘big AG’ situations (re: above context about consolidations) such as macro-farms approaching or already embodied in corporate filing status.
So while I have breath in me and while I still work a high tech day job to feed my family, I will continue to find ways to gain more context and come up with truly meaningful tech opportunities to positively impact small/mid-sized farm businesses. If I don’t, who will? You? If yes, then let’s connect and do good things together.
Footnotes
Re: good vs. bad company signals
Be wary of expectations to ‘rep’ (-resent) company agendas (such as in modern developer advocacy, on pay-to-play webinars, or promotional content that is ‘forever-licensed’ with my name/face on it) and certainly where sales/solutions engineering requires this, doing so under very clear on-calls activities. I despise when companies require or mandate that employees use their own personal social media accounts to promote product stuff; even when the product is awesome, there are more useful and effective ways to promote products/services. I equally detest corporate policies to ‘sign the waiver’ over ‘your likeness and materials’, as especially with AI image gen going the way it has, also predicates that companies with this permission can create chatbots and promo videos using your visual and audio identity in any future they want to do so. I have never and never will sign any agreements like this.
I do voluntarily socialize when cultural things are working well in an employer, often through publicly encouraging colleagues and highlighting their successes. Anyone can look up how we’re connected and who we work for, so the ‘advertisement’ is more about who is behind the scenes more than the products or services themselves. People deserve credit where it is due and while people above them often fail to acknowledge it, I do not.
]]>