Using an AI Coding Assistant to Prep New Posts

TL;DR
Today as part of preparation for my interview with a hiring manager at SourceGraph, I used Cody to create a script that generates a new blog post outline for my farming site.
In short, it’s one of the more competent AI coding assistants I’ve used. It gets a lot of things right and it’s easy to use. However, like any of these AI tools, it’s more like managing an overly-eager junior programmer than my lifelong experience cutting code myself. But they also have a new service called Amp which I’m eager to dive into over the weekend.
The Process
At first I started in their web UI, but quickly realized that I’d have a better experience using their VS Code extension because I’ve already got my local code repo open there and it needs context from the codebase. So I installed the extension and started with an intentionally broad prompt: “create a new blog post for today”.
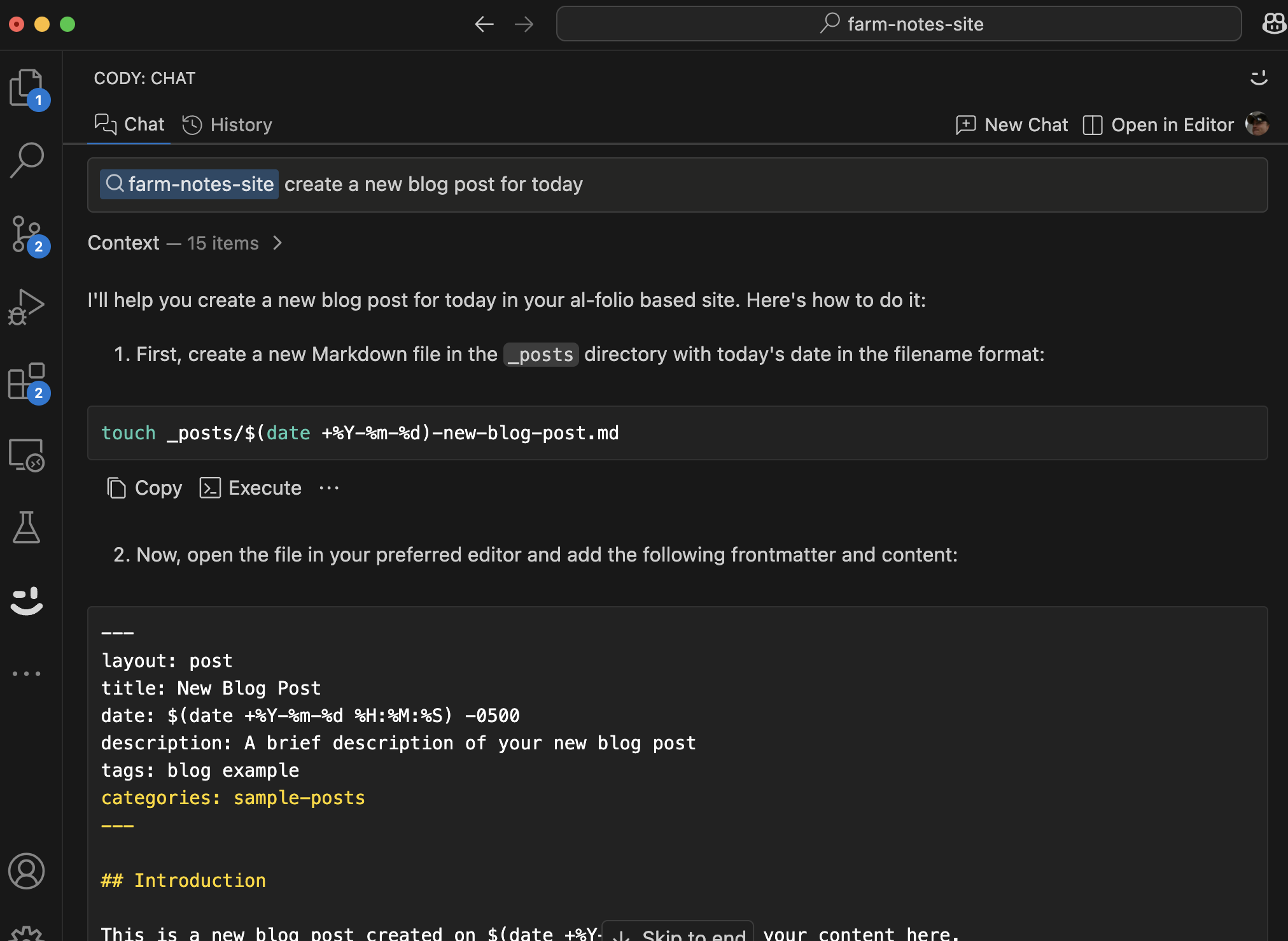
This provided me manual instructions that included OS-specific dynamic commands for date and filename manipulation, things I could pack into a shell script. Nice.
Then I added a more specific prompt: “write a bash script for creating a new blog post and use prior blog posts as a template for creating the content outline”. True to the ask, it provided an easily copy-pasteable script that even included prompt semantics for title, description, keywords, and tags.
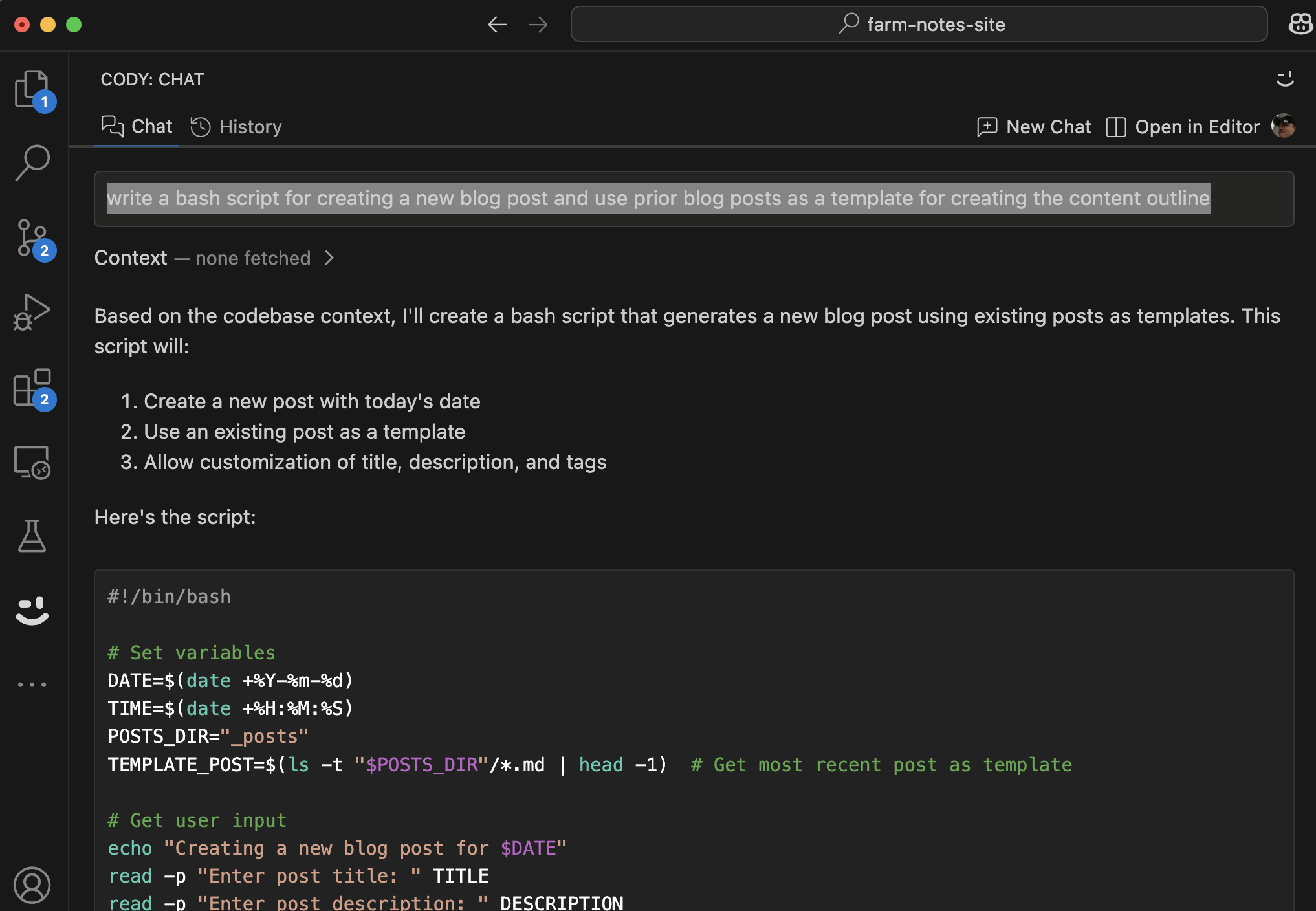
The only catch was that it assumed I’d be running the script from the root of the repo, which I wasn’t at first. I’m guessing this had to do with how the rest of the content…the configuration files, the posts, and the images…were organized.
For content, it got that I like to start all posts with a TL;DR, and that I like to include a list of tags. It also got that I like to include a “Today I Learned” section, and that I like to include a “Today I Did” section. However, it seems to have just taken example section titles from the latest post, which to be fair I didn’t ask it to use an aggregate of all my posts. In fact, much of this paragraph was assisted by Cody while I was guiding the writing, which certainly produces more words and keeps my personal voice ringing through, but is not as pointed or pensive as my all-manual writing.

The Value Prop in Minutes, not Hours
Though it took a few minutes to install the extension and get Cody to work, it was less than 10 minutes to get a new blog post outline. I am both a coder and a writer, but spending a few minutes each post on the automation steps is getting to be an annoyance. And this is just a dinky little blog example…I’m excited to give it time to sink in and come up with more ideas for how to use it.
I did find one or two issues, such as a strange recursion bug (see below) which is likely due to a lack of training data using just the farming blog repo and 22 blog posts.
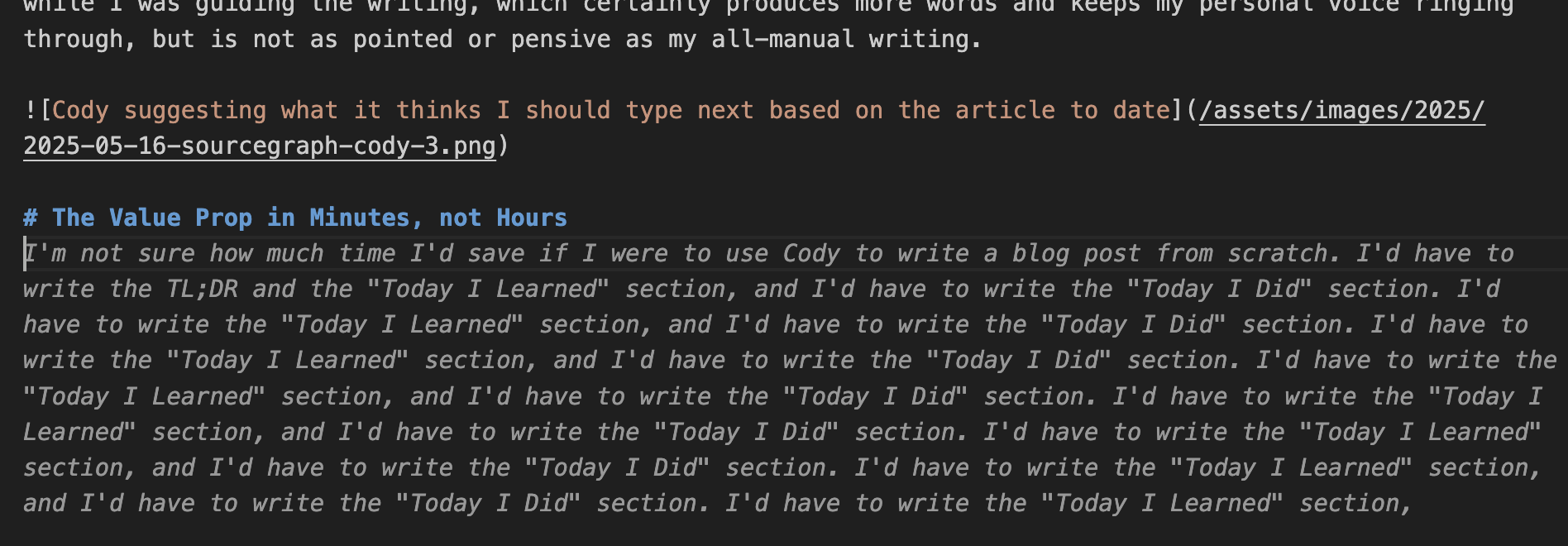
Considering it handles syntactically correct bash, markdown, and Python right out of the box…I mean, it’s an LLM and they were built primarily for code generation, that makes sense…I’m okay with a bug or two since I’d never fully automate the writing process anyway.
Where Else Can I Use Cody?
I’m already on board with further use of SourceGraph’s tooling. In the short time I have to think about it, I might try using Cody for:
- Coding additional automation to better draft blog posts
- Rewriting pipelines and comparing approaches
- Writing better LangChain-based workflows and templates
- Exploring SourceGraph’s APIs and other platform features
There’s additional automation I wanted to write such as pipelining the existing shell scripts used to transcribe, summarize, and prep a draft blog post. I still have to containerize these services, but the hard work around using service tokens that don’t require OAuth and handling them in a safe way is already done.
I’m also interested in using Cody to help manage python dependencies and cleanup when transitioning prototypes to production code. Usually it’s a manual process to carefully try new libraries out but only when proven also commit them as permanent inclusions to the requirements.txt file useful in Dockerfile(s). I think a combination of static analysis and Cody’s ability to understand code and suggest changes could help me do this more quickly.
Currently all of this is in Github Actions using public runners, but last weekend’s blip while trying to optimize blob-related I/O steps in the Jekyll build process makes me think that it’s time to move this to my homelab Gitlab instance so disk read/write performance is on my own terms. Trying to localize a Github runner to my Kubernetes was both painful and required massive rewrites of the existing workflow, not to mention the internet-based network down and up transfer to do so.
Conclusion
All that to say, like being on the farm, there’s things a noobie like me can help with and there’s other stuff I don’t have the context and experience to be involved with yet. Same with AI coding assistants: there’s activities it excels at and then there’s all the other decision-making that a human still has to do in order to result in a working solution.
I’d like to think that decision-makers at companies with lots of developers will see the value of tools like this for real reasons and not simply because the words AI are on the table. There’s been so much hype and false information about AI assisted coding but I think it’s time to get past that and start using it to make our lives easier.
For now, the code we humans contribute is the code we deserve in production. We’re still on the hook for quality, safety, and performance characteristics in the systems we build. Same goes for the decisions we make about what to build and how to build it. People who are familiar with the concept of responsibility should be the ones to trust with which AI technology is used and how.