Automating the Quality of Your Digital Front Door
Mobile is the front door to your business for most / all of your users. But how often do you use your front door, a few times a day? How often do your users use your app? How often would you like them to? It’s really a high-traffic front door between people and you.
This is how you welcome people into what you’re doing. If it’s broken, people don’t feel welcome.
[7/27/2017: For my presentation at Mobile Tea Boston, my slides and code samples are below]
Slides with notes: http://bit.ly/2tgGiGr
Git example: https://github.com/paulsbruce/FingerprintDemo
The Dangers of Changing Your Digital Front Door
In his book “On Intelligence”, Hawkins describes how quickly our human brains pick up on minute changes with the analogy of someone replacing the handle on your front door with a knob while you’re out. When you get back, things will seem very weird. You feel disoriented, alienated. Not emotions we want to invoke in our users.
Now consider what it’s like for your users to have you changing things on their high-traffic door to you. Change is good, but only good changes. And when changes introduce problems, forget sympathy, forget forgiveness, people revolt.
What Could Possibly Go Wrong?
A lot. Even for teams that are great at what they do, delivering a mobile app is fraught with challenges that lead to:
- Lack of strategy around branching, merging, and pushing to production
- Lack of understanding about dependencies, impacts of changes
- Lack of automated testing, integration woes, no performance/scalability baselines, security holes
- Lack of communication between teams (Front-end, API, business)
- Lack of planning at the business level (marketing blasts, promotions, advertising)
Users don’t care about our excuses. A survey by Perfecto found that more than 44% of defects in mobile apps are found by users. User frustrations aren’t just about what you designed, they are about how they behave in the real world too. Apps that are too slow will be treated as broken apps and uninstalled just the same.
What do we do about it?
We test, but testing is a practice unto itself. There are many test types and methodologies like TDD, ATDD, and BDD that drive us to test. Not everyone is cut out to be a great tester, especially when developers are driven to write only things that works, and not test for when it shouldn't (i.e. lack of negative testing).
[caption id="attachment_701" align="alignright" width="279"]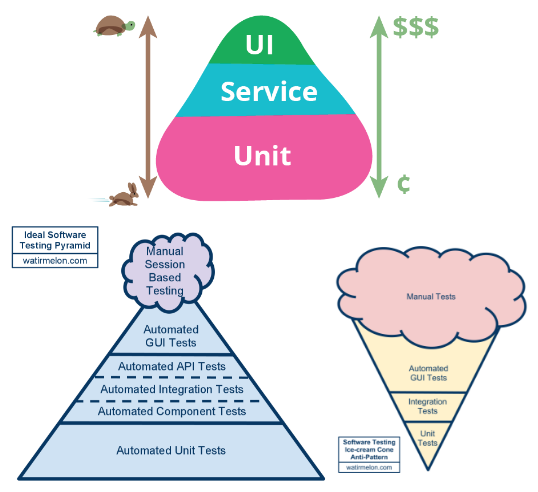 Allistar Scott - Test 'Ice Cream Cone'[/caption]
Allistar Scott - Test 'Ice Cream Cone'[/caption]
In many cases, automation gaps and issues make it easier for development teams to fall back to manual testing. This is what Allistar Scott (of Ruby Waitr) calls the anti-pattern 'ice cream cone', an inversion of the ideal test pyramid, and Mike Cohen has good thoughts on this paradigm too.
To avoid this downward spiral, we need to prioritize automation AND which tests we chose to automate. Testing along architecturally significant boundaries, as Kevin Henney puts it, is good; but in a world full of both software and hardware, we need to broaden that idea to 'technologically significant boundaries'. The camera, GPS, biometric, and other peripheral interfaces on your phone are a significant boundary...fault lines of the user experience.
Many development teams have learned the hard way that not including real devices in automated testing leaves these UX fault lines at risk of escaping defects. People in the real world use real devices on real networks under real usage conditions, and our testing strategy should reflect this reality too.
The whole point of all this testing is to maintain confidence in our release readiness. We want to be in an 'always green' state, and there's no way to do this without automated, continuous testing.
Your Code Delivery Pipeline to the Rescue!
Confidence comes in two flavors: quality and agility. Specifically, does the code we write do what we intend, and can we iterate and measure quickly?
Each team comes with their own definition of done, their own acceptable levels of coverage, and their own level of confidence over the what it takes to ship, but answering both of these questions definitively requires adequate testing and a reliable pipeline for our code.
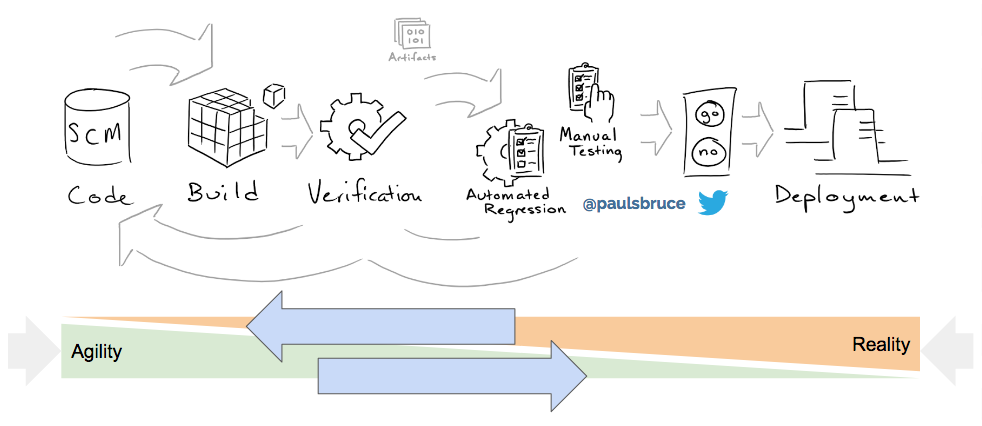
Therein lies the dynamic tension between agility (nimbleness) and the messy world of reality. What’s the point of pushing out something that doesn’t match the needs of reality? So we try to pull reality in little bits at a time, but reality can be slow. Executing UI tests takes time. So we need to code and test in parallel, automate as much as possible, and be aware of the impact of changes on release confidence.
The way we manage this tension is to push smaller batches more frequently through the pipeline, bring the pain forward, in other words continuous delivery and deployment. Far away from monolithically, we shrink the whole process to an individual contributor level. Always green at the developer level...merge only code that has been tested automatically, thoroughly.
Even in a Perfect World, Your Front Door Still Jams
So automation is crucial to this whole thing working. But what happens when we can’t automate something? This is often why the “ice cream cone” exists.
Let’s walk through it together. Google I/O or WWDC drops new hardware or platform capabilities on us. There’s a rush to integrate, but a delay in tooling and support gums up development all the way through production troubleshooting. We mock what we have to, but fall back to manual testing.
This not only takes our time, it robs us of velocity and any chance to reach that “always green” aspiration.
The worst part is that we don’t even have to introduce new functionality to fall prey to this problem. Appium was stuck behind lack of iOS 10 support for months, which means most companies had no automated way to validate on a platform that was out already.
And if anything, history teaches us that technology advances whether the last thing is well-enough baked or not. We are still dealing with camera (i.e. driver stack) flakiness! Fingerprint isn’t as unreliable, but still part of the UI/UX. And many of us now face an IoT landscape with very few standards that developers follow.
So when faced with architectural boundaries that have unpolished surfaces, what do we do? Mocks...good enough for early integration, but who will stand up and say testing against mocks is good enough to go to production?
IoT Testing Provides Clues to How We Can Proceed
In many cases, introducing IoT devices into the user experience means adding architecturally significant boundaries. Standards like BLE, MQTT, CoAP and HTTP provide flexibility to virtualize much of the interactions across these boundaries.
In the case of Continuous Glucose Monitoring (CGM) vendors, their hardware and mobile app dev cycles are on very different cycles. But to integrate often, they virtualize BLE signals to real devices in the cloud as part of their mobile app test scripts. They also adopt “IoT ninjas” as part of the experience team, hardware/firmware engineers that are in change of prototyping changes on the device side, to make sure that development and testing on the mobile app side is as enabled as possible.
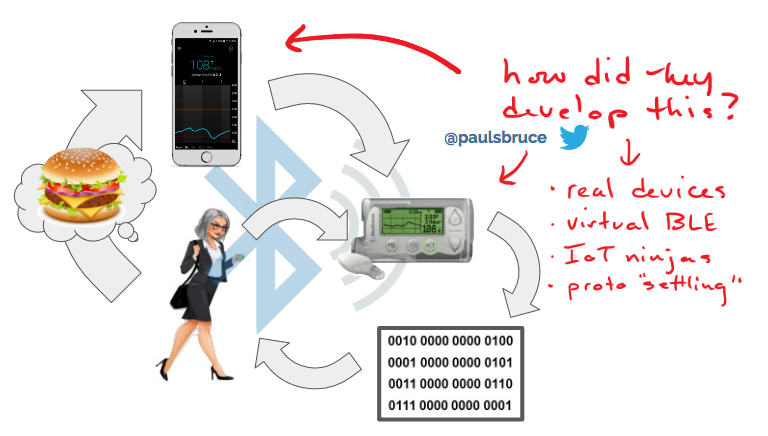
Adding IoT to the mix will change your pyramid structure, adding pressure to rely on standards/interfaces as well as manual testing time for E2E scenarios.
[For more on IoT Testing, see my deck from Mobile/IoT Dev+Test 2017 here]
Automated Testing Requires Standard Interfaces

There are plenty of smart people looking to solve the busy-work problem with writing tests. Facebook Infer, Appdiff, Functionalize, and MABL are just a few of the new technologies that integrate machine learning and AI to reduce time-spend on testing busy-work.
But any and all programmatic approach, even AI, requires standard interfaces; in our case, universally accepted development AND testing frameworks and technologies.
Tool ecosystems don’t get built without foundational standards, like HTML/CSS/JS, Android, Java, and Swift. And when they want to innovate on hardware or platform, there will always be some gaps, usually in automation around the new stuff.
Example Automation Gap: Fingerprint Security
Unfortunately for those of us who see the advantages of integrating with innovative platform capabilities like biometric fingerprint authentication, automated testing support is scarce.
What this means is that we either don't test certain critical workflows in our app, or we manually test them. What a bummer to velocity.
The solution is to have people who know how to implement multiple test frameworks and tools in a way that matches the velocity requirements of development.

For more information in this, see my deep-dive on how to use Appium in Android development to simulate fingerprint activities in automated tests. It's entirely possible, but requires experience and a planning over how to integrate a mobile lab into your continuous integration pipeline.
Tailoring Fast Feedback to Resources (and vice versa)
As you incrementally introduce reality into every build, you’ll run into two problems: execution speed and device pool limits.
To solve the execution speed, most development teams parallelize their testing against multiple devices at once, and split up their testing strategy to different schedules. This is just an example of a schedule against various testing types.
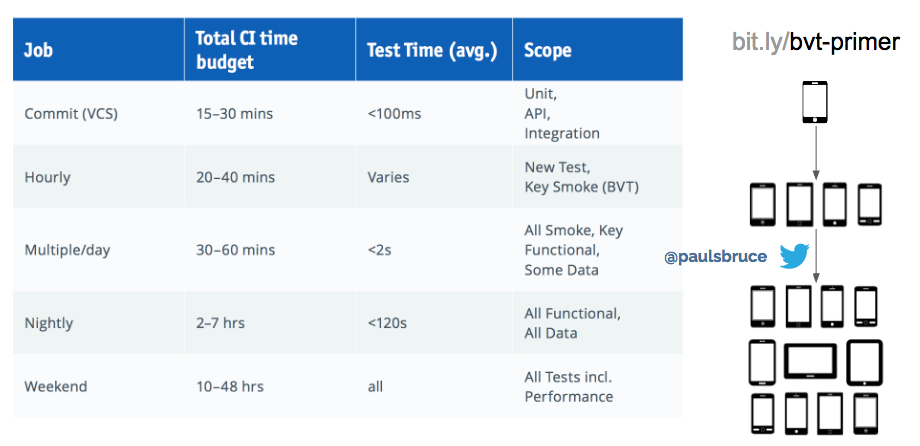
For more on this, I published a series of whitepapers on how to do this.
TL;DR recap
Automating the quality of our web and mobile apps keeps us accurate, safe, and confident; but isn't easy. Fortunately we have many tools and a lot of thought put in already to how to do this. Notwithstanding ignorance of some individuals, automation continues to change the job landscape over and over again.
Testing always takes tailoring to the needs of the development process to provide fast feedback. The same is true in reverse: developers need to understand where support gaps exist in test frameworks and tooling, otherwise they risk running the "ship" aground.
This is why, and my mantra remains, it is imperative to velocity to have the right people in the planning room when designing new features and integrating capabilities across significant technological boundaries.
Similarly, in my research on developer efficiency, we see that there is a correlation between increased coverage over non-functional criteria on features and test coverage. Greater completeness in upfront planning saves time and effort, it's just that simple.
Just like Conway’s “law”, the result of your team, it’s structure, communication patterns, functions and dysfunctions, all show up in the final product. Have the right people in the room when planning new features, retros, and determining your own definition of done. Otherwise you end up with more gaps than simply in automation.
Meta / cliff notes:
- “Everyone owns quality” means that the whole team needs to be involved in testing strategy
- To what degree are various levels of testing included in Definition of Done?
- Which test sets (i.e. feedback loops) provide the most value?
- How are various tests triggered, considering their execution speed?
- Who's responsible for creating which types of tests?
- How are team members enabled to interpret and use test result data?
- When defects do escape certain stages, how is RCA used to close the gap?
- Who manages/fixes the test execution framework and infrastructure?
- Does the benefits of the current approach to testing outweigh the cost?
- Multiple testing framework / tool / platform is 200 OK
- We already use separate frameworks for separate test types
- jUnit/TestNG (Java) for unit (and some integration) testing
- Chakram/Citrus/Postman/RestAssured for API testing
- Selenium, Appium, Espresso, XCTest for UI testing
- jMeter, Dredd, Gatling, Siege for performance testing
- Tool sprawl can be a challenge, but proper coverage requires plurality
- Don't overtax one framework or tool to do a job it can't, just find a better fit
- We already use separate frameworks for separate test types
- Incremental doses of reality across architecturally significant boundaries
- We need reality (real devices, browsers, environments) to spot fragility in our code and our architecture
- Issues tend to clump around architecturally significant boundaries, like API calls, hardware interfaces, and integrations to monolithic components
- We stub/mock/virtualize to speed development; signs of "significant" boundaries, but it only tells us what happens in isolation
- A reliable code pipeline can do the automated testing for you, but you still need to tell it what and when to test; have a test execution strategy that considers:
- testing types (unit, component, API, integration, functional, performance, installation, security, acceptance/E2E, ...)
- execution speed (<2m, <20m, <2h, etc) vs. demand for fast feedback
- portions of code that are known-fragile
- various critical-paths: login, checkout, administrative tasks, etc.
- Annotations denote tests that relate across frameworks and tools
- @Signup, @Login, @SearchForProduct, @V2Deploy
- Tag project-based work (like bug fixes) like: JIRA-4522
- Have the right people in the room when planning features
- Future blockers like test framework support for new hardware capabilities will limit velocity, so have test engineers in the planning phases
- Close the gap between what was designed vs. what is feasible to implement by having designers and developers prototype together
- Including infrastructure/operations engineers in planning reduces later scalability issues; just like testers, this can be a blocker to release readiness
- Someone, if not all the people above, should represent the user's voice
More reading:
- On Intelligence, Jeff Hawkins
- Branch Permissions for your Git repositories
- Continuous Integration Doesn't Work
- Why Apps Fail, a Survey of Mobile Users
- The Test Pyramid - Martin Fowler
- The Forgotten Layer of the Test Automation Pyramid - Mike Cohen
- Allistar Scott - The Test Pyramid Ice Cream Cone Anti-pattern
- Kevin Henney, "Code at Risk" (architectural boundaries), Goto Conference
- Blockchain on IoT - Fingerprint Security for Your Bitcoin Wallet, FTSafe
- DON'T PANIC (or how to prepare for IoT with a mature test strategy)
- Facebook Infer - AI tool squashes bugs with intelligent static code analysis
- Appdiff - the first API-powered mobile testing platform
- AI for software testing closes the coverage gap between tests and features
- MABL - machine intelligence for microservices and apps
- A Developer's Guide to Build-time Quality - Paul Bruce
- The Path to Releasing Confidently in DevOps - Paul Bruce, Peter Crocker